
Once we have the model we should evaluate its performance and tune it to improve its performance. If a data mining model is bad, it’s usually pretty easy to identify from the features, the validation procedure, or the goodness metrics. With diagnostic metrics, there are different measures, different metrics for different methods. First we will focus on methods for classifiers and later we’ll discuss metrics for regressors.
A simple benchmark to start with is comparing the model performance to the baseline model. For classification problem the baseline model is to guess the output class that has the largest proportion in the training samples. For regression problem, the best guess will be the mean of output of training samples.
Measuring Regression Performance For regression problem, the distance between the estimated output and the actual output is used to quantify the model’s performance. Some of the metrics for regressors include:
- Linear correlation, also called Pearson’s correlation
- Mean absolute deviation
- Root mean squared error
- Information Criteria
Linear correlation is the measure of the strength and direction of the linear relationship between two variables. Coefficient Of Determination or R squared is just the correlation squared. It’s also a measure of what percentage of variance in the predicted variable is explained by your model. If you’re predicting A with B, C, D, and E, R2 is often used as the measure of model goodness rather than R. The mean absolute error or the mean absolute deviation is simply the average of the absolute value of the actual value minus the predicted value. The mean absolute error tells you the average amount to which the predictions deviate from the actual values, which is very interpretable. RMSE is root mean square error. It is computed by taking the difference between the actual value and the predictive value and squaring before taking its average and the square root. Root mean squared error can be interpreted the same way as mean absolute deviation mostly, but it penalizes large deviations more than small deviations. MAE vs RMSE The difference between the mean absolute error and the root mean squared error is that they’re both taking the differences between each data point’s actual value and predictive value, but in the case of the mean absolute error, we are just averaging those while in the case of root mean squared error, we are squaring those, averaging them, and then taking the square root. The mean absolute error is very interpretable. It tells us the average amount to which the predictions deviate from the actual values. Root mean squared error can be interpreted the same way mostly, but it penalizes large deviations more than small deviations. RMSE is a bit harder to interpret as compared to MAE but it should be preferred over MAE as demonstrated below: Let there be a machine which produces a good quality product 70% of the time. Remaining 30% of time the product is faulty. Here: 1 => Good Quality; 0=> Bad quality We have two models to predict the quality of the product. Their response is as below: Model A is predicts Quality = 0.7 Model B is predicts Quality = 1 

As per MAE, Model B has lower error while as per RMSE, Model A is better. Intuitively Model A does seem better because it is predicting that the output will be good 70 percent of the time which is the reality unlike model B which is predicting that the output will always be good even though it is only good 70 percent of the time. Thus RMSE is coming with a more reasonable result than mean absolute error.
Information Criteria Bayesian information criterion ot BiC, makes a trade-off between the goodness of fit and flexibility of fit, or in other words the number of parameters. The formula for linear regression, called BiC’, is a function number of data points, number of variables, and correlation.
BiC’ = n log(1 – r2) + p log n N = number of data points ; p = number of variables.
BiC’ is very interpretable. If you got a value over 0, then your model is worse than expected given the number of variables. If you got a value under 0 then your model is better than expected given the number of variables. You can also use them to understand how significant is the difference between two models. It turns out that the BiC’ differences of 6 or 10 between two models is statistically significant difference according to Raftery. AIC is an alternative to BiC. It stands for Akaike’s information criterion. Akaike’s information criterion makes slightly different trade-off between the goodness of fit and the flexibility of fit.
Measuring Classification Performance Confusion Matrix: A convenient tool for performance evaluation is the so-called confusion matrix, which is a square matrix that consists of columns and rows that list the number of instances as “actual class” vs. “predicted class” ratios.
| Actual/ Predicted | Positive Prediction | Negative Prediction |
| True data | TP | FN |
| False Data | FP | TN |
- TP = Predict +ve when Actual +ve
- TN = Predict -ve when Actual -ve
- FP = Predict +ve when Actual -ve
- FN = Predict -ve when Actual +ve
Sensitivity (synonymous to recall) and precision are assessing the “True Positive Rate” for a binary classification problem: The probability to make a correct prediction for a “positive/true” case. Precision is when your model says something is true, how often is it right. It is the probability that a data point classified as true is actually true.
In other words it is the probability that you are diseased, given that the test is positive.
Precision = P(disease| +ive test)
Precision = TP/(TP+FP)
Sensitivity or recall is of the cases that actually are 1’s in the data, what percentage of time do you actually capture them? It is the probability that a data point that is actually true is classified as true. In other words if you really are diseased then what is the probability that we predict it correctly.
Sensitivity = P(+ive test | disease)
Sensivity = TP/(TP+FN)
Precision and sensitivity are different in the sense that in precision we are looking at all the cases which model as predicted as 1 and finding out what fraction of them is actually 1. Whereas in sensitivity we look at the cases which are actually 1 and find out what fraction of them our model has correctly predicted as 1.
Specificity describes the “True Negative Rate” for a binary classification problem: The probability to make a correct prediction for a “false/negative” case (e.g., in an attempt to predict a disease, no disease is predicted for a healthy patient).
In other words if you are really healthy, what’s the probability we test it correctly.
Specificity = P(-ive test | No disease)
Specificity = TN/(TN + FP)
Accuracy is the probability that we correctly classified an outcome. Accuracy is the number of agreements divided by the total number of codes or assessments.
Accuracy = (TP + TN) / (TP + TN + FP + FN)
There’s general agreement across fields that accuracy is not a good metric.
The problem is that when we have highly unbalanced classes. Let say if 99% of the data have y = 0, to get high accuracy, all you have to do is predict y = 0 regardless of the features in the data set. This shows that your model is accurate only because the classes are so highly unbalanced, but it is not good at actually differentiating between the two classes. So despite having accuracy of 99 percent, my detector is completely useless. It has no information at all.
You can sample from your data set to obtain a balanced sample or penalize the model for missclassifying the minority class. Interesting article here: http://statistics.berkeley.edu/sites/default/files/tech-reports/666.pdf
A metric like AUC, Gini or KS would be better for comparing models and evaluating model fit when we have highly unbalanced classes. These statistics rank order the predictions and remove the effect of unbalanced classes. Even with an unbalanced sample, if you predict y = 0 for all of your data, you will get AUC = 0.5. Keep in mind that you also want to use a hold out sample for these evaluation metrics.
ROC and AUC
ROC is receiver-operating characteristic curve. With ROC curves, you are predicting something which has two values like yes or no. Your prediction model is outputting a probability or other real value. And you want to ask the question, how good is your prediction model?
With an ROC curve what you do is you take any number and use it as a cut-off. Whatever number you choose, some number of predictions, maybe 0, is then going to be classified as 1’s and the rest, again maybe 0, will be classified as 0’s.
Let’s look at an example. Let’s say that you have the following predictions to your model and the following ground truth.

So, let’s say we take a case with the threshold 0.5. As we see in the highlighted cell that prediction for 0.55 is wrong at this threshold. So, we say our threshold is 0.6, then two of them flip 0.55 and 0.53. While one become true the other one gets wrongly classified.
This actually doesn’t make the model any better because in one case that makes something that was wrong right and the other case it makes thing that was right wrong. 0.55 was previously wrong, now it’s right because now it’s below 0.6 so it’s 0 which is the truth and 0.53 was previously above and it 1’s that was correct, now it is below and that’s wrong. So you can see that as we change the thresholds, some of the data points go from being right to wrong in each direction.
| Threshold = 0.5 | Threshold = 0.6 | |
| Instance 0.55 | Wrongly Classified | Rightly Classified |
| Instance 0.53 | Rightly Classified | Wrongly Classified |
There are four possibilities for any classification threshold.
- True positive. Both the model and the data say it’s 1.
- False positive. The data says it’s 0, but the model says it’s 1.
- True negative. Both the data and the model say it’s 0.
- False negative where the data says that it’s 1, but the model says it’s 0.
And you’ll get a different blend of these four possibilities as you change your threshold. So what’s an ROC curve from all that? An ROC curve graphs two relations. – X axis is the percent FP/ TN. So of the cases where the data are 0, what percentage of them are actually classified correctly by the detector and what percentage of them are classified incorrectly meaning false positives – Y axis is TP/ FN. So of the data that’s truly positive, of the data that’s 1, what percentage of them do we say that’s true positives versus false negatives? And the true positives go up and the false negatives go down. The lower left point (0, 0) represents the strategy of never issuing a positive classification; such a classifier commits no false positive errors but also gains no true positives. The opposite strategy, of unconditionally issuing positive classifications, is represented by the upper right point (1, 1).
As cited in paper by John Taylor – “The point (0, 1) represents perfect classification. Informally, one point in ROC space is better than another if it is to the northwest (tp rate is higher, fp rate is lower, or both) of the first. Classifiers appearing on the left-hand side of an ROC graph, near the X axis, may be thought of as ‘‘conservative’’: they make positive classifications only with strong evidence so they make few false positive errors, but they often have low true positive rates as well. Classifiers on the upper right-hand side of an ROC graph may be thought of as ‘‘liberal’’: they make positive classifications with weak evidence so they classify nearly all positives correctly, but they often have high false positive rates.”
So, let’s look an example.

We can see the false positive ratios on the X axis, true positive ratios on the Y axis. So this model, for anywhere along the curve is actually got more true positives by a proportion than false positives until we get to the very top corner. That dash line is chance.
AUC or A’
ROC curve tells us about the tradeoffs, however of we actually want to know which of the prediction algorithms is better we can quantify one curve versus the other by calculating the area under the curve. Higher the area the better the predictor.
A’ is the probability that if you give a model an example from each category, it will accurately identify which is which. A’ is what percentage of time your model can get correctly classify any instance rightly. The AUC of a classifier is equivalent to the probability that the classifier will rank a randomly chosen positive instance higher than a randomly chosen negative instance. A’ of 0.6 is always better than A’ of 0.55 and it’s very easier to interpret statistically. A’ values are almost always higher than Kappa values and that’s something that sometimes can confuse you. It closely mathematically approximates the area under the ROC curve which is also called AUC. A’ is more difficult to compute and it only works for two categories without complicated extensions. But the meaning is invariant across data sets.
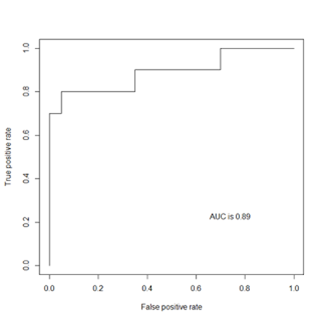
There are few observations regarding AUC:
- It has value between [0,1]
- The Higher the value of AUC the better is distinguishing capability of the classifier
- AUC = 0.5 is a random classifier. It is bad.
- AUC < 0.5 is actually worse than random guessing. It means that you labeling 1s as 0s and vice versa.
- AUC = 1 is a perfect classifier
- AUC >= 0.8 is an indication of a good classifier.
Kappa (Agreement – Expected Agreement) / (1-Expected Agreement) So of the total distance you can go from whatever the expected agreement is to perfect, Kappa is how far you are along that scale, what percentage of the way you are. How to calculate Kappa? Kappa depends on:
- % Agreement and between real data and prediction model
- % Expected Agreement between real data and prediction model
% Agreement is given by the % instances which have been correctly classified by the model. Given below is a confusion matrix for a model and agreement % thereof.

Expected Agreement = Expected Agreement on instances classified as 0 + Expected Agreement on instances classified as 1 P(D0) = Probability of a randomly picked instance from data is ‘0’ = Frequency of ‘0’ instances in data P(M0) = Probability of a random instance being classified as ‘0’ by model = Frequency of ‘0’ classifications as per the model. P(D1) = Probability of a randomly picked instance from data is ‘1’ = Frequency of ‘1’ instances in data P(M1) = Probability of a random instance being classified as ‘1’ by model = Frequency of ‘1’ classifications as per the model.  Expected Agreement b/w data and model on instances classified as 0 = P(D0) * P(M0) Expected Agreement b/w data and model on instances classified as 1 = P(D1) * P(M1) Kappa = (0.8 – 0.575) / (1-0.575) = 0.225 / 0.425 = 0.529 So this model is 52.9 percent of the way from expected agreement to perfect. That is the model was about 52.9 percent better than base rate or simple put 52.9% better than chance.
Expected Agreement b/w data and model on instances classified as 0 = P(D0) * P(M0) Expected Agreement b/w data and model on instances classified as 1 = P(D1) * P(M1) Kappa = (0.8 – 0.575) / (1-0.575) = 0.225 / 0.425 = 0.529 So this model is 52.9 percent of the way from expected agreement to perfect. That is the model was about 52.9 percent better than base rate or simple put 52.9% better than chance.
Interpreting Kappa
Kappa = 0: Agreement is at chance, expected frequency. Kappa equals 0, not good.
Kappa = 1. Your agreement’s perfect.
Kappa = – ∞. Agreement is perfectly inverse. Every time the data says 0, the detector says 1 and vice versa
Kappa > 1. Impossible – something wrong with the computation.
– ∞ < Kappa < 0: This means your model is worse than chance, it is junk. And what it really means is that your model goes in opposite direction in the training set and in your test set, which really is not something you want.
0 < Kappa < 1: Normal Range There’s no absolute standard for a good measure of Kappa in the above range. If you’ve got a data mining model, typically 0.3 to 0.5 is good enough to call the model better than chance and go ahead and publish it. Why is there no standard? Why can’t people just say, ah yes, 0.4, that’s my magic number. Or 0.8, that’s really what we should use. The problem is that Kappa is scaled by the proportion of each category. So you really shouldn’t be looking for magic numbers, because in fact, Kappa is influenced by the data set you’re in. When one class is much more prevalent, expected agreement’s going to be higher than if the classes are evenly balanced. So it’s harder to get a good Kappa in variance balanced data. Part of the point of Kappa is to deal with the fact that you have imbalanced data, but in fact, it kind of biases against you when you have imbalanced data. The opposite of accuracy, which bias is in favor. The biases of Kappa are much weaker than the biases of accuracy. It’s a much better metric, but it’s not perfect. Because of this, comparing Kappa values between two data sets in a principled fashion is difficult. It is OK to compare Kappa values within a data set. And so comparing Kappa values between data sets or saying 0.6 or 0.8 is magic Kappa and you’ve going to be better than that, well, it kind of ignores what Kappa. Informally, you can kind of compare two data sets if the proportions of each category of similar, but it’s really something to think about carefully.
Source of error: Bias and Variance Bias: Error from erroneous assumptions in the learning algorithm. It implies that we are using an over-simplified model to represent the underlying data.. For example, a linear regression model would have high bias when trying to model a quadratic relationship – no matter how you set the parameters, you can’t get a good training set error. Variance: Error from sensitivity to small fluctuations in the training set. It is about the stability of your model in response to new training examples. High-variance model may be able to represent their training set well, but are at risk of overfitting. It is not generalizing well to the underlying data pattern. High variance usually happen when there is insufficient training data compare to the number of model parameters.
High Bias: If the problem is a high-bias problem collecting more data would not help beyond a certain limit.
High Variance: While fitting a complex model to data if the training data is insufficient as compared to the number of model parameters then a problem of High Variance occurs resulting in overfitting If High variance is due to overestimating the model complexity when a simpler model can fit the data then adding more data will not help. However, when the underlying data model is in fact complex and can be explained by a complicated model then errors due to high variance can be minimized by adding more data. To fix the issue High Bias -> Increase Model Complexity -> If the data set is small, add some more examples. High Variance: Simplify the model or Add more data (model can’t be simplified)
References: http://horicky.blogspot.in/2012/06/predictive-analytics-evaluate-model.html https://followthedata.wordpress.com/2012/06/02/practical-advice-for-machine-learning-bias-variance/ http://gim.unmc.edu/dxtests/roc2.htm
